

To accelerate the transition to memory safe programming languages, the US Defense Advanced Research Projects Agency (DARPA) is driving the development of TRACTOR, a programmatic code conversion vehicle.
The term stands for TRanslating All C TO Rust. It’s a DARPA project that aims to develop machine-learning tools that can automate the conversion of legacy C code into Rust.
The reason to do so is memory safety. Memory safety bugs, such buffer overflows, account for the majority of major vulnerabilities in large codebases. And DARPA’s hope is that AI models can help with the programming language translation, in order to make software more secure.
“You can go to any of the LLM websites, start chatting with one of the AI chatbots, and all you need to say is ‘here’s some C code, please translate it to safe idiomatic Rust code,’ cut, paste, and something comes out, and it’s often very good, but not always,” said Dan Wallach, DARPA program manager for TRACTOR, in a statement.
“You can go to any of the LLM websites, start chatting with one of the AI chatbots, and all you need to say is ‘here’s some C code, please translate it to safe idiomatic Rust code,’ cut, paste, and something comes out, and it’s often very good, but not always,” said Dan Wallach, DARPA program manager for TRACTOR, in a statement.
“This parlor trick impressed me. I’m sure it can scale to solve difficult real world problems.”
It’s a promising approach worth trying, but I won’t be holding my breath.
If DARPA really wanted safer languages, they could be pushing test coverage, not blindly converting stable well tested C code into untested Rust code.
This, like most AI speculation, reeks of looking for shortcuts instead of doing the boring job at hand.
It reeks of a consultant who sold upper management via a gated demo.
You would also port the tests, right?
You would also port the tests, right?
Right… If they exist.
But that bit shouldn’t be left to a hallucination prone AI.
You have tests?
Edit: guess could always use AI to auto generate tests /s
I mean the parent comment mentioned tests…
Also:
As to the possibility of automatic code conversion, Morales said, “It’s definitely a DARPA-hard problem.” The number of edge cases that come up when trying to formulate rules for converting statements in different languages is daunting, he said.
I’m thinking they also want to future proof this.
The quantity of C devs are dying. It’s a really difficult language to get competent with.
That’s a really valid point.
A really unfortunate one too.
If DARPA really wanted safer languages, they could be pushing test coverage,
Or Ada…
Ada is not strictly safer. It’s not memory safe for example, unless you never free. The advantage it has is mature support for formal verification. But there’s literally no way you’re going to be able to automatically convert C to Ada + formal properties.
In any case Rust has about a gazillion in-progress attempts at adding various kinds of formal verification support. Kani, Prusti, Cruesot, Verus, etc. etc. It probably won’t be long before it’s better than Ada.
Also if your code is Ada then you only have access to the tiny Ada ecosystem, which is probably fine in some domains (e.g. embedded) but not in general.
A: “We really need this super-important and highly-technical job done.”
B: “We could just hire a bunch of highly-technical people to do it.”
A: “No, we would have to hire people and that would cost us millions.”
B: “We could spend billions on untested technology and hope for the best.”
A: “Excellent work B! Charge the government $100M for our excellent idea.”
turning C code automatically into Rust…
Oh wow they must have some sick transpiler, super exciting…
With AI, of course
God fucking damnit.
You want Skynet? 'Cause that’s how you get Skynet.
Maybe, but it’s gonna be more like SkyNet with electrolytes; it’s what terminators crave.
deleted by creator
Too bad commenters are as bad as reading articles as LLMs are at handling complex scenarios. And are equally as confident with their comments.
This is a pretty level headed, calculated, approach DARPA is taking (as expected from DARPA).

On a bit serious note, flux.1 model is pretty good…
Key detail in the actual memo is that they’re not using just an LLM. “Wallach anticipates proposals that include novel combinations of software analysis, such as static and dynamic analysis, and large language models.”
They also are clearly aware of scope limitations. They explicitly call out some software, like entire kernels or pointer arithmetic heavy code, as being out of scope. They also seem to not anticipate 100% automation.
So with context, they seem open to any solutions to “how can we convert legacy C to Rust.” Obviously LLMs and machine learning are attractive avenues of investigation, current models are demonstrably able to write some valid Rust and transliterate some code. I use them, they work more often than not for simpler tasks.
TL;DR: they want to accelerate converting C to Rust. LLMs and machine learning are some techniques they’re investigating as components.
It’d be nice if they open source this like they did with ghidra. The video game reverse engineering and modernization efforts have been much easier thanks to the government open sourcing their tools
Ghidra is open source?! How did I miss this!
c2rust: Am I a joke to you?
I threw some simple code at it and it even put
unsafeon the main function, what’s the point of Rust then if everything isunsafe?For all of our sake, I hope humans are the final set of eyes before the code is used in prod.
And I hope that’s not someone who doesn’t understand the
statickeyword after 2+ years of C++ development.
Ideally you don’t directly ship the code it outputs, you use it instead of re-writing it from scratch and then slowly clean it up.
Like Mozilla used it for the initial port of qcms (the colour management library they wrote for Firefox), then slowly edited the code to be idiomatic rust code. Compare that to something like librsvg that did a function by function port
Baby steps. It’s easier to convert code marked unsafe in Rust to not need unsafe than it is convert arbitrary code in other languages to Rust code that doesn’t need unsafe.
This is an interesting application of so-called AI, where the result is actually desirable and isn’t some sort of frivolity or grift. The memory-safety guarantees offered by native Rust code would be a very welcome improvement over C code that guarantees very little. So a translation of legacy code into Rust would either attain memory safety, or wouldn’t compile. If AI somehow (very unlikely) manages to produce valid Rust that ends up being memory-unsafe, then it’s still an advancement as the compiler folks would have a new scenario to solve for.
Lots of current uses of AI have focused on what the output could enable, but here, I think it’s worth appreciating that in this application, we don’t need the AI to always complete every translation. After all, some C code will be so hardware-specific that it becomes unwieldy to rewrite in Rust, without also doing a larger refactor. DARPA readily admits that their goal is simply to improve the translation accuracy, rather than achieve perfection. Ideally, this means the result of their research is an AI which knows its own limits and just declines to proceed.
Assuming that the resulting Rust is: 1) native code, and 2) idiomatic, so humans can still understand and maintain it, this is a project worth pursuing. Meanwhile, I have no doubt grifters will also try to hitch their trailer on DARPA’s wagon, with insane suggestions that proprietary AI can somehow replace whole teams of Rust engineers, or some such nonsense.
Edit: is my disdain for current commercial applications of AI too obvious? Is my desire for less commercialization and more research-based LLM development too subtle? :)
The problem I see here is that AI may write code that does compile, but has a bunch of logical errors, edge cases or bad architecture. From personal experience, even though AI can write small amounts of good code, it’s bad at understanding big and complex solutions.
At that point, fixing the AI codebase might take longer than just starting with a competent Rust dev.
This is a timely reminder and informative for people who aren’t aware that LLMs don’t actually understand anything. At all.
That doesn’t mean they’re useless, but yes, if you want an LLM to handle complex input and use it to generate complex output correctly… You may need to reevaluate your choice of tooling or your process.
This is a timely reminder and informative for people who want to seem smug I guess? Or haven’t really thought about it? … that the word “understand” is definitely not defined precisely or restrictively enough to exclude LLMs.
By the normal meaning of “understand” they definitely show some level of understanding. I mean, have you used them? I think current state of the art LLMs could actually pass the Turing test against unsophisticated interviewers. How can you say they don’t understand anything?
Understanding is not a property of the mechanism of intelligence. You can’t just say “it’s only pattern matching” or “it’s only matrix multiplication” therefore it doesn’t understand.
I think understanding requires knowledge, and LLMs work with statistics around text, not knowledge.
With billions of dollars pumped into these companies and enough server farms crawling to make a data hoarder green with envy, they’ve reached a point where it seems like they know things. They’ve incorporated, in some capacity, that some things are true, and some are related. They understand.
That is not the case. Ask me a thousand times the solution of a math problem, and a thousand times I’ll give you the same solution. Ask an LLM about a math problem, and you’ll get different strategies, different rules, and different answers, often incorrect. Same thing with coding. Back away a little, and you could even apply that to any task with reasoning.
But you don’t need to go that far: ask an LLM about anything without sufficient resources on the internet to absorb, and it’ll just make things up. Because an LLM has no concept of knowing, it also has no concept of not knowing. It knows anything about as well as your smartphone keyboard. It’s autocomplete on steroids.
So let’s say they understand—they contain information about—the statistical relations between tokens. That’s not the same as understanding what those tokens actually mean, and the proof of that is how much basic stuff LLMs get wrong, all the time. The information they hold is about the tokens themselves, not about the real world things those tokens represent.
At this point, I don’t think it’s unreasonable to say that insisting LLMs understand anything is a discussion more related to the meaning of words than to current AI capabilities. In fact, since understanding is more closely associated with knowledge that you can reason with and about, the continuous use of this word in these discussions can actually be harmful by misleading people who don’t know better.
This is a timely reminder and informative for people who want to seem smug I guess?
Thanks for assuming good faith, I suppose.
I mean, have you used them?
I have, in fact, used multiple popular LLM models currently available, including paid offerings, and spent way too much time hearing both people who know about this subject and people who don’t. I can safely say LLMs don’t understand anything. At all.
How can you say they don’t understand anything?
See above.
I think understanding requires knowledge, and LLMs work with statistics around text, not knowledge.
You’re already making the assumption that “statistics around text” isn’t knowledge. That’s a very big assumption that you need to show. And before you even do that you need a precise definition of “knowledge”.
Ask me a thousand times the solution of a math problem, and a thousand times I’ll give you the same solution.
Sure but only if you are certain of the answer. As soon as you have a little uncertainty that breaks down. Ask an LLM what Obama’s first name is a thousand times and it will give you the same answer.
Does my daughter not have any knowledge because she can’t do 12*2 reliably 1000 times in a row? Obviously not.
it’ll just make things up
Yes that is a big problem, but not related to this discussion. Humans can make things up too, the only difference is they don’t do it all the time like LLMs do. Well actually I should say most humans don’t. I worked with a guy who was very like an LLM. Always an answer but complete bullshit half the time.
they contain information about—the statistical relations between tokens. That’s not the same as understanding what those tokens actually mean
Prove it. I assert that it is the same.
You’re already making the assumption that “statistics around text” isn’t knowledge. That’s a very big assumption that you need to show.
And you’re making the assumption that it could be. Why am I the only one who needs to show anything?
I’m saying that LLMs fail at many basic tasks that any person which could commonly be said to have an understanding of them wouldn’t. You brought up the Turing test as though it was an actual, widely accepted scientific measure of understanding.
Turing did not explicitly state that the Turing test could be used as a measure of “intelligence”, or any other human quality.
Nevertheless, the Turing test has been proposed as a measure of a machine’s “ability to think” or its “intelligence”. This proposal has received criticism from both philosophers and computer scientists. […] Every element of this assumption has been questioned: the reliability of the interrogator’s judgement, the value of comparing the machine with a human, and the value of comparing only behaviour. Because of these and other considerations, some AI researchers have questioned the relevance of the test to their field.
Sure but only if you are certain of the answer. As soon as you have a little uncertainty that breaks down.
What do you mean, “certain of the answer?” It’s math. I apply knowledge, my understanding gained through study, to reason about and solve a problem. Ask me to solve it again, the rules don’t change; I’ll get the same answer. Again, what do you mean?
Ask an LLM what Obama’s first name is a thousand times and it will give you the same answer.
Apples to oranges. “What’s Obama’s first name” doesn’t require the same kind of skills as solving a math problem.
Also, it took me 7 attempts to get ChatGPT to be confidently wrong about Obama’s name:
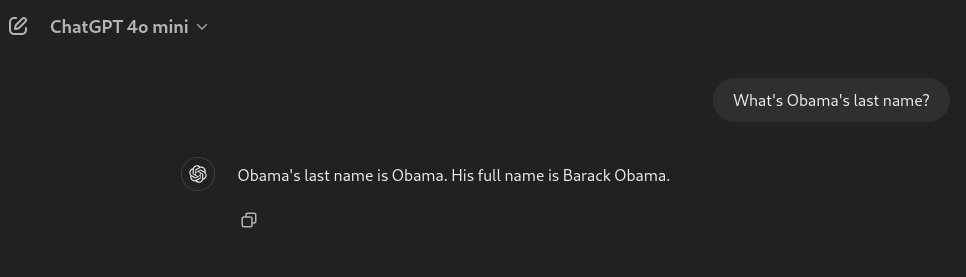
It couldn’t even give me the same answer 7 times.
Does my daughter not have any knowledge because she can’t do 12*2 reliably 1000 times in a row? Obviously not.
That’s not my argument. If your daughter hasn’t learned multiplication yet, there’s no way she could guess the answer. Once has grown and learned it, though, I bet she’ll be able to answer that reliably. And I fully believe she’ll understand more about our world than any LLM. I hope you do so as well.
it’ll just make things up
Yes that is a big problem, but not related to this discussion.
It’s absolutely related, because as I stated, LLMs have no concept of knowing. Even if there are humans that’ll lie, make things up, spread misinformation—sometimes even on purpose—at least there are also humans who won’t. People who’ll try to find the truth. People that will say, “Actually, I’m not sure. Why don’t we look into it together?”
LLMs don’t do that, and they fundamentally can’t. Any insurmountable objection to answering questions is a guardrail put in place by their developers, and researchers are already looking into how to subvert those.
I worked with a guy who was very like an LLM. Always an answer but complete bullshit half the time.
Sorry to hear that. From experience, I know they can cause a lot of damage, even unintentionally.
That’s not the same as understanding what those tokens actually mean
Prove it. I assert that it is the same.
Very confident assertion, there. Can I ask where’s your proof?
I see that you also neglected to answer a critical part of my comment, so I’ll just copy and paste it here.
At this point, I don’t think it’s unreasonable to say that insisting LLMs understand anything is a discussion more related to the meaning of words than to current AI capabilities. In fact, since understanding is more closely associated with knowledge that you can reason with and about, the continuous use of this word in these discussions can actually be harmful by misleading people who don’t know better.
Any opinion on this?
And you’re making the assumption that it could be. Why am I the only one who needs to show anything?
“Could be” is the null hypothesis.
any person
Hmm I’m guessing you don’t have children.
What do you mean, “certain of the answer?” It’s math
Oh dear. I dunno where to start here… but basically while maths itself is either true or false, our certainty of a mathematical truth is definitely not. Even for the cleverest mathematicians there are now proofs that are too complicated for humans to understand. They have to be checked by machines… then how much do you trust that the machine checker is bug free? Formal verification tools often have bugs.
Just because something “is math” doesn’t mean we’re certain of it.
Can I ask where’s your proof?
I don’t have proof. That’s my point. Your position is no stronger than the opposite position. You just asserted it as fact.
deleted by creator
so-called AI
knows its own limits
frustration noises It knows nothing! It’s not intelligent. It doesn’t understand anything. Attempts to keep those things acting within expected/desired lines fail constantly, and not always due to malice. This project’s concept reeks of laziness and trend-following. Instead of a futile effort to make a text generator reliably produce either an error or correct code, they should perhaps put that effort into writing a transpiler built on knowable, understandable rules. … Oh, and just hire a damn Rust dev. They’re climbing up the walls looking to Rust-ify everything, just let them do it.
So a translation of legacy code into Rust would either attain memory safety, or wouldn’t compile.
They’d probably have to make sure it doesn’t use the
unsafekeyword to guarantee this.
Thirty percent of the time it works all of the time!
Can someone explain more of the difference between C and Rust to a non programmer?
There is a ton of literature out there, but in a few words:
Rust is built from the ground up with the intention of being safe, and fast. There are a bunch of things you can do when programming that are technically fine but often cause errors. Rust builds on decades of understanding of best practices and forces the developer to follow them. It can be frustrating at first but being forced to use best practices is actually a huge boon to the whole community.
C is a language that lets the developer do whatever the heck they want as long as it’s technically possible. “Dereferencing pointer 0?” No problem boss. C is fast but there are many many pitfalls and mildly incorrect code can cause significant problems, buffer overflows for example can open your system to bad actors sending information packets to the program and cause your computer to do whatever the bad actor wants. You can technically write code with that problem in both c and rust, but rust has guardrails that keep you out of trouble.
But if they have fully tested and safe C, and they’re converting it to Rust using AI, that seems more dangerous, not less.
Just recently a bug was found in openssh that would let you log into the root user of any machine. With extreme skill and luck of course, but it was possible.
OpenSsh is probably one of the most safe C programs out there with the most eyes on it. Since it’s the industry standard to remotely log in into any machine.
There is no such thing as fully tested and safe C. You can only hope that you find the bug before the attacker does. Which requires constant mantainance.
The the about rust is that the code can sit there unchanged and “rust”. It’s not hard to make a program in 2019 that hasn’t needed any maintainance since then, and free of memory bugs.
Just so you know, that bug was a months long hack, probably by a State actor, not just something they didn’t spot before.
It still goes to show that there’s no fully tested C code. I’m sure OpenSSH has had the eyes of thousands of security researchers in it. Yet it still has memory-related bugs.
There is no fully tested and safe C. There’s only C that hasn’t had a buffer overflow, free after use, … yet.
It’s hyperbole, but the amount of actually tested C without bugs is few and far between. Most C/C++ code doesn’t have unit, nor integration tests, and I have barely seen fuzzing (which seems to be the most prominent out there).
free after use
That would be perfectly safe in any language.
use after free, whoops
Safest C is a Hello World program.
That’s a pretty good explanation. So along the same level of explanation, what are these memory problems they are talking about?
I explained a little about buffer overflows, but in essence programming is the act of making a fancy list of commands for your computer to run one after the other.
One concept in programming is an “array” or list of things, sometimes in languages like C the developer is responsible for keeping track of how many items are in a list. When that program accepts info from other programs (like a chat message, video call, website to render, etx) in the form of an array sometimes the sender can send more info than the developer expected to receive.
When that extra info is received it can actually modify the fancy list of commands in such a way that the data itself is run directly on the computer instead of what the developer originally intended.
Bad guy sends too much data, at the end of the data are secret instructions to install a new program that watches every key you type on your keyboard and send that info to the bad guy.
Many thanks.
deleted by creator
C: Older systems developing language, pretty much industry standard to the point the C-style syntax is often a feature of other languages. Its biggest issues include a massive lack of syntax sugar, such as having to do
structTypeFunction(structInstance)rather thanstructInstance.function()as standard in more modern languages, use of header files and a precompiler (originally invented to get around memory limitations and still liked by hard-core C fans, otherwise disliked by everyone else), and lack of built-in memory safety features, which is especially infamous with its null-terminated strings, often being part of many attack vectors and bugs.Rust: Newer memory-safe language with functional programming features, most notably const by default, and while it does use curly braces for scopes (code blocks), the general syntax is a bit alien to the C-style of languages. Due to its heavy memory safety features, which also includes a borrow checker, not to mention the functional programming aspects, it’s not a drop in replacement language for C to the point you pretty much have too reimplement the algorithms in functional style.
I can somewhat see the issue with memory safety, but the other issues are fine by me.
Even then, D would be a better drop-in replacement, especially in BetterC mode, since it has a currently optional memory safety feature, which is planned to be less optional in a possible Version 3. I personally only have ran into an issue that would have been solved by a “const by default” approach (meaning a function had an unintended side effect, for which the functional approach is to disallow side effects as much as possible), but it would be extra annoying for my own purpose (game development).
The biggest fixer of “unintended side effects” is memory safety, since you won’t have memory overwrites.
c is for femboys, rust is for trans people
Looking at your instance handle, I hope/assume that your comment is supposed to be in lighthearted jest. However that would only be an assumption on my part and in general it’s not ok to say someone’s job/work tool is for [remarks directed at sex, gender, ethnicity, orientation, disabilities, etc…] per CoC 3.5.
Please take into consideration that members on this instance may be of different backgrounds than what you’re used to and interpets what you say differently. Further breaches of our Code of Conduct may lead to temporary or permament ban.
Using an LLM to come up with function names for transpiled code would be a good idea, but other than that. Nope.







