

if you could pick a standard format for a purpose what would it be and why?
e.g. flac for lossless audio because…
(yes you can add new categories)
summary:
- photos .jxl
- open domain image data .exr
- videos .av1
- lossless audio .flac
- lossy audio .opus
- subtitles srt/ass
- fonts .otf
- container mkv (doesnt contain .jxl)
- plain text utf-8 (many also say markup but disagree on the implementation)
- documents .odt
- archive files (this one is causing a bloodbath so i picked randomly) .tar.zst
- configuration files toml
- typesetting typst
- interchange format .ora
- models .gltf / .glb
- daw session files .dawproject
- otdr measurement results .xml
Just going to leave this xkcd comic here.
Yes, you already know what it is.
One could say it is the standard comic for these kinds of discussions.
There are too many of these comics, I’ll make one to be the true comic response and unite all the different competing standards
🪛
how did i know it was standards
now, proliferate
Open Document Standard (.odt) for all documents. In all public institutions (it’s already a NATO standard for documents).
Because the Microsoft Word ones (.doc, .docx) are unusable outside the Microsoft Office ecosystem. I feel outraged every time I need to edit .docx file because it breaks the layout easily. And some older .doc files cannot even work with Microsoft Word.
Actually, IMHO, there should be some better alternative to .odt as well. Something more out of a declarative/scripted fashion like LaTeX but still WYSIWYG. LaTeX (and XeTeX, for my use cases) is too messy for me to work with, especially when a package is Byzantine. And it can be non-reproducible if I share/reuse the same document somewhere else.
Something has to be made with document files.
Markdown, asciidoc, restructuredtext are kinda like simple alternatives to LaTeX
There is also https://github.com/typst/typst/
It is unbelievable we do not have standard document format.
What’s messed up is that, technically, we do. Originally, OpenDocument was the ISO standard document format. But then, baffling everyone, Microsoft got the ISO to also have
.docxas an ISO standard. So now we have 2 competing document standards, the second of which is simply worse.That’s awful, we should design something that covers both use cases!
I was too young to use it in any serious context, but I kinda dig how WordPerfect does formatting. It is hidden by default, but you can show them and manipulate them as needed.
It might already be a thing, but I am imagining a LaTeX-based standard for document formatting would do well with a WYSIWYG editor that would hide the complexity by default, but is available for those who need to manipulate it.
There are programs (LyX, TexMacs) that implement WYSIWYG for LaTeX, TexMacs is exceptionally good. I don’t know about the standards, though.
Another problem with LaTeX and most of the other document formats is that they are so bloated and depend on many other tasks that it is hardly possible to embed the tool into a larger document. That’s a bit of criticism for UNIX design philosophy, as well. And LaTeX code is especially hard to make portable.
There used to be a similar situation with PDFs, it was really hard to display a PDF embedded in application. Finally, Firefox pdf.js came in and solved that issue.
The only embedded and easy-to-implement standard that describes a ‘document’ is HTML, for now (with Javascript for scripting). Only that it’s not aware of page layout. If only there’s an extension standard that could make a HTML page into a document…
I was actually thinking of something like markdown or HTML forming the base of that standard. But it’s almost impossible (is it?) to do page layout with either of them.
But yeah! What I was thinking when I mentioned a LaTeX-based standard is to have a base set of “modules” (for a lack of a better term) that everyone should have and that would guarantee interoperability. That it’s possible to create a document with the exact layout one wants with just the base standard functionality. That things won’t be broken when opening up a document in a different editor.
There could be additional modules to facilitate things, but nothing like the 90’s proprietary IE tags. The way I’m imagining this is that the additional modules would work on the base modules, making things slightly easier but that they ultimately depend on the base functionality.
IDK, it’s really an idea that probably won’t work upon further investigation, but I just really like the idea of an open standard for documents based on LaTeX (kinda like how HTML has been for web pages), where you could work on it as a text file (with all the tags) if needed.
Finally, Firefox pdf.js came in and solved that issue.
Which uses a bloated and convoluted scripting format specialized on manipulating html.
True, but it offered a much more secure alternative to opening up PDFs locally.
I don’t think so. pdf.js has all few monts a new XSS CVE, which is a web thing only. And if you use anything other than Adobe Reader/Acrobat…
Bro, trying to give padding in Ms word, when you know… YOU KNOOOOW… they can convert to html. It drives me up the wall.
And don’t get me started on excel.
Kill em all, I say.
zip or 7z for compressed archives. I hate that for some reason rar has become the defacto standard for piracy. It’s just so bad.
The other day I saw a tar.gz containing a multipart-rar which contained an iso which contained a compressed bin file with an exe to decompress it. Soooo unnecessary.
Edit: And the decompressed game of course has all of its compressed assets in renamed zip files.
A .tarducken, if you will.
Ziptarar?
It was originally rar because it’s so easy to separate into multiple files. Now you can do that in other formats, but the legacy has stuck.
Not just that. RAR also has recovery records.
.tar.zstdall the way IMO. I’ve almost entirely switched to archiving with zstd, it’s a fantastic format.why not gzip?
Gzip is slower and outputs larger compression ratio. Zstandard, on the other hand, is terribly faster than any of the existing standards in means of compression speed, this is its killer feature. Also, it provides a bit better compression ratio than gzip citation_needed.
Yes, all compression levels of gzip have some zstd compression level that is both faster and better in compression ratio.
Additionally, the highest compression levels of zstd are comparable in compression level to LZMA while also being slightly faster in compression and many many times faster in decompression
gzip is very slow compared to zstd for similar levels of compression.
The zstd algorithm is a project by the same author as lz4. lz4 was designed for decompression speed, zstd was designed to balance resource utilization, speed and compression ratio and it does a fantastic job of it.
The only annoying thing is that the extension for zstd compression is zst (no d). Tar does not recognize a zstd extension, only zst is automatically recognized and decompressed. Come on!
If we’re being entirely honest just about everything in the zstd ecosystem needs some basic UX love. Working with .tar.zst files in any GUI is an exercise in frustration as well.
I think they recently implemented support for chunked decoding so reading files inside a zstd archive (like, say, seeking to read inside tar files) should start to improve sooner or later but some of the niceties we expect from compressed archives aren’t entirely there yet.
Fantastic compression though!
-Ioption?Not sure what that does.
Yes, you can use options to specify exactly what you want. But it should recognize
.zstdas zstandard compression instead of going “I don’t know what this compression is”. I don’t want to have to specify the obvious extension just because I typed zstd instead of zst when creating the file.
.tar.xz masterrace
This comment didn’t age well.
This is the kind of thing i think about all the time so i have a few.
- Archive files:
.tar.zst- Produces better compression ratios than the DEFLATE compression algorithm (used by
.zipandgzip/.gz) and does so faster. - By separating the jobs of archiving (
.tar), compressing (.zst), and (if you so choose) encrypting (.gpg),.tar.zstfollows the Unix philosophy of “Make each program do one thing well.”. .tar.xzis also very good and seems more popular (probably since it was released 6 years earlier in 2009), but, when tuned to it’s maximum compression level,.tar.zstcan achieve a compression ratio pretty close to LZMA (used by.tar.xzand.7z) and do it faster[1].zstd and xz trade blows in their compression ratio. Recompressing all packages to zstd with our options yields a total ~0.8% increase in package size on all of our packages combined, but the decompression time for all packages saw a ~1300% speedup.
- Produces better compression ratios than the DEFLATE compression algorithm (used by
- Image files:
JPEG XL/.jxl- “Why JPEG XL”
- Free and open format.
- Can handle lossy images, lossless images, images with transparency, images with layers, and animated images, giving it the potential of being a universal image format.
- Much better quality and compression efficiency than current lossy and lossless image formats (
.jpeg,.png,.gif). - Produces much smaller files for lossless images than AVIF[2]
- Supports much larger resolutions than AVIF’s 9-megapixel limit (important for lossless images).
- Supports up to 24-bit color depth, much more than AVIF’s 12-bit color depth limit (which, to be fair, is probably good enough).
- Videos (Codec):
AV1- Free and open format.
- Much more efficient than x264 (used by
.mp4) and VP9[3].
- Documents:
OpenDocument / ODF / .odt- @raubarno@lemmy.ml says it best here.
.odtis simply a better standard than.docx.
it’s already a NATO standard for documents Because the Microsoft Word ones (.doc, .docx) are unusable outside the Microsoft Office ecosystem. I feel outraged every time I need to edit .docx file because it breaks the layout easily. And some older .doc files cannot even work with Microsoft Word.
- @raubarno@lemmy.ml says it best here.
deleted by creator
.tar is pretty bad as it lacks in index, making it impossible to quickly seek around in the file.
.tar.pixz/.tpxz has an index and uses LZMA and permits for parallel compression/decompression (increasingly-important on modern processors).
It’s packaged in Debian, and I assume other Linux distros.
Only downside is that GNU tar doesn’t have a single-letter shortcut to use pixz as a compressor, the way it does “z” for gzip, “j” for bzip2, or “J” for xz (LZMA); gotta use the more-verbose “-Ipixz”.
Also, while I don’t recommend it, IIRC gzip has a limited range that the effects of compression can propagate, and so even if you aren’t intentionally trying to provide random access, there is software that leverages this to hack in random access as well. I don’t recall whether someone has rigged it up with tar and indexing, but I suppose if someone were specifically determined to use gzip, one could go that route.
- By separating the jobs of archiving (
.tar), compressing (.zst), and (if you so choose) encrypting (.gpg),.tar.zstfollows the Unix philosophy of “Make each program do one thing well.”.
wait so does it do all of those things?
So there’s a tool called tar that creates an archive (a
.tarfile. Then theres a tool called zstd that can be used to compress files, including.tarfiles, which then becomes a.tar.zstfile. And then you can encrypt your.tar.zstfile using a tool called gpg, which would leave you with an encrypted, compressed.tar.zst.gpgarchive.Now, most people aren’t doing everything in the terminal, so the process for most people would be pretty much the same as creating a ZIP archive.
- By separating the jobs of archiving (
By separating the jobs of archiving (.tar), compressing (.zst), and (if you so choose) encrypting (.gpg), .tar.zst follows the Unix philosophy of “Make each program do one thing well.”.
The problem here being that GnuPG does nothing really well.
Videos (Codec): AV1
- Much more efficient than x264 (used by .mp4) and VP9[3].
AV1 is also much younger than H264 (AV1 is a specification, x264 is an implementation), and only recently have software-encoders become somewhat viable; a more apt comparison would have been AV1 to HEVC, though the latter is also somewhat old nowadays but still a competitive codec. Unfortunately currently there aren’t many options to use AV1 in a very meaningful way; you can encode your own media with it, but that’s about it; you can stream to YouTube, but YouTube will recode to another codec.
The problem here being that GnuPG does nothing really well.
Could you elaborate? I’ve never had any issues with gpg before and curious what people are having issues with.
Unfortunately currently there aren’t many options to use AV1 in a very meaningful way; you can encode your own media with it, but that’s about it; you can stream to YouTube, but YouTube will recode to another codec.
AV1 has almost full browser support (iirc) and companies like YouTube, Netflix, and Meta have started moving over to AV1 from VP9 (since AV1 is the successor to VP9). But you’re right, it’s still working on adoption, but this is moreso just my dreamworld than it is a prediction for future standardization.
Could you elaborate? I’ve never had any issues with gpg before and curious what people are having issues with.
This article and the blog post linked within it summarize it very well.
Encrypting Email
Don’t. Email is insecure . Even with PGP, it’s default-plaintext, which means that even if you do everything right, some totally reasonable person you mail, doing totally reasonable things, will invariably CC the quoted plaintext of your encrypted message to someone else
Okay, provide me with an open standard that is widely-used that provides similar functionality.
It isn’t there. There are parties who would like to move email users into their own little proprietary walled gardens, but not a replacement for email.
The guy is literally saying that encrypting email is unacceptable because it hasn’t been built from the ground up to support encryption.
I mean, the PGP guys added PGP to an existing system because otherwise nobody would use their nifty new system. Hell, it’s hard enough to get people to use PGP as it is. Saying “well, if everyone in the world just adopted a similar-but-new system that is more-amenable to encryption, that would be helpful”, sure, but people aren’t going to do that.
The message to be taken from here is rather “don’t bother”, if you need secure communication use something else, if you’re just using it so that Google can’t read your mail it might be ok but don’t expect this solution to be secure or anything. It’s security theater for the reasons listed, but the threat model for some people is a powerful adversary who can spend millions on software to find something against you in your communication and controls at least a significant portion of the infrastructure your data travels through. Think about whistleblowers in oppressive regimes, it’s absolutely crucial there that no information at all leaks. There’s just no way to safely rely on mail + PGP for secure communication there, and if you’re fine with your secrets leaking at one point or another, you didn’t really need that felt security in the first place. But then again, you’re just doing what the blog calls LARPing in the first place.
deleted by creator
.odt is simply a better standard than .docx.
No surprise, since OOXML is barely even a standard.
is av1 lossy
AV1 can do lossy video as well as lossless video.
I get better compression ratio with xz than zstd, both at highest. When building an Ubuntu squashFS
Zstd is way faster though
wait im confusrd whats the differenc ebetween .tar.zst and .tar.xz
Different ways of compressing the initial
.tararchive.Having “double” extensions is a terrible convention for operating systems where extensions actually matter and users are used to them, like Windows.
“.tar.xz” should be something like “.tarxz” or “.txz”
But it’s not a tarxz, it’s an xz containing a tar, and you perform operations from right to left until you arrive back at the original files with whatever extensions they use.
If I compress an exe into a zip, would you expect that to be an exezip? No, you expect it to be file.exe.zip, informing you(and your system) that this file should first be unzipped, and then should be executed.
it’s an xz containing a tar
So what? When you zip 5 documents together do you name it .zip or .config.lib.sh.deb.zip?
No, you expect it to be a file.exe.zip
Double extensions are not conventional on Windows, so no, I do not.
Dots in filenames are commonly used in any operating system like name_version.2.4.5.exe or similar… So I don’t see a problem.
deleted by creator
use a real operative system then
Sounds like a Windows problem
Cool. So it means it’s a problem for over 70% of all active desktop and laptop computers.
I get the frustration, but Windows is the one that strayed from convention/standard.
Also, i should’ve asked this earlier, but doesn’t Windows also only look at the characters following the last dot in the filename when determining the file type? If so, then this should be fine for Windows, since there’s only one canonical file extension at a time, right?
You’re absolutely correct when it comes to how Windows will interpret the file - it will ignore all the preceding “extensions” and will use the last one as the filetype and as the hook for whatever default action or application should handle it. However, getting people used to double extensions is one quick way of increasing the success rate of attacks such as the infamous “.pdf.exe” invoice from an email attachment. It also creates issues with renaming files and, though admittedly not many, some Windows application’s own file pickers.
Still - from just a theoretical point of view, I can’t see how Windows’ convention is worse, in fact, it makes significantly more sense. If I zip a file, it doesn’t matter what it was in a previous life, it’s now a zip - this is also how Unix deals with many filetypes, I’ve never seen a .h264.mp4 file, even though the .mp4 container can actually represent different types of encoding. Why have one filetype use the Windows convention and another, for no reason, a different one?
I get your point. Since a
.tar.zstfile can be handled natively bytar, using.tzstinstead does make sense.There already are conventional abbreviations: see Section 2.1. I doubt they will be better supported by tools though.
That’s much better. Thanks for actually answering the comment, rather than the usual “Windows bad, Linux good, upvotes please”
In this case it really seems this windows convention is bad though. It is uninformative. And abbreviations mandate understanding more file extensions for no good reason. And I say this as primarily a windows user. Hiding file extensions was always a bad idea. It tries to make a simple reduced UI in a place where simple UI is not desirable. If you want a lean UI you should not be handling files directly in the first place.
Example.zip from the other comment is not a compressed .exe file, it’s a compressed archive containing the exe file and some metadata. Windows standard tools would be in real trouble trying to understand unarchived compressed files many programs might want to use for logging or other data dumps. And that means a lot of software use their own custom extensions that neither the system nor the user knows what to do with without the original software. Using standard system tools and conventions is generally preferable.
I would argue what windows does with the extensions is a bad idea. Why do you think engineers should do things in favour of these horrible decisions the most insecure OS is designed with?
Damn didn’t realize that JXL was such a big deal. That whole JPEG recompression actually seems pretty damn cool as well. There was some noise about GNOME starting to make use of JXL in their ecosystem too…
- Archive files:
Ogg Opus for all lossy audio compression (mp3 needs to die)
7z or tar.zst for general purpose compression (zip and rar need to die)
The existence of zip, and especially rar files, actually hurts me. It’s slow, it’s insecure, and the compression is from the jurassic era. We can do better
@dinckelman @Supermariofan67 I think you mean unsecure. It doesn’t feel unsure of itself. 😁
in·se·cure (ĭn′sĭ-kyo͝or′) adj.
- Inadequately guarded or protected; unsafe: A shortage of military police made the air base insecure.
https://www.thefreedictionary.com/insecure
Unsecure
a. 1. Insecure.
@hungprocess touché.
One thing I didn’t appreciate about English until reading a Europe forum for a while is that it has a lot of different prefixes that mean something like “not”, and this is not very intuitive to people learning the language. Their use is not regular.
Consider:
-
“a-” as in “atypical”
-
“non-” as in “nonconsentual”
-
“un-” as in “uncooperative”
-
“im-” as in “immortal”
-
“in-” as in “inconsiderate”
-
“il-” as in “illegitimate”
-
“mal-” as in “maladjusted”
-
“anti-” as in “anti-establishment”
-
“de-” as in “deconstruct”
And sometimes, some of the prefixes are associated with base words to form real words with similar meanings, but meanings that are not the same. For example, “immoral” and “amoral” do not mean the same thing, though they have related meanings.
-
@hungprocess Also this. https://english.stackexchange.com/questions/19653/insecure-or-unsecure-when-dealing-with-security
It seems that I was quite wrong, but that a lot of other people are wrong as well. lol
why does zip and rar need to die
Zip has terrible compression ratio compared to modern formats, it’s also a mess of different partially incompatible implementations by different software, and also doesn’t enforce utf8 or any standard for that matter for filenames, leading to garbled names when extracting old files. Its encryption is vulnerable to a known-plaintext attack and its key-derivation function is very easy to brute force.
Rar is proprietary. That alone is reason enough not to use it. It’s also very slow.
Again, I’m not the original poster. But zip isn’t as dense as 7zip, and I honestly haven’t seen rar are used much.
Also, if I remember correctly, the audio codecs and compression types. The other poster listed are open source. But I could be mistaken. I know at least 7zip is and I believe opus or something like that is too
Most mods on Nexus are in rar or zip. Also most game cracks; or as iso, which is even worse.
I have seen RAR on Nexus, but I wouldn’t say that it’s common, at least for Bethesda’s games, which is where I’ve seen it.
Things may have changed, but I recall that yenc (for ASCII encoding), RAR (for compression and segmenting) and PAR2 (for redundancy) were something of a standard for binary distribution on Usenet, and that’s probably the main place I’ve seen RAR. I think that the main selling point there was that it was just a format that was widely-available that supported segmented files.
That would explain why I don’t see them often. I haven’t been very active in gaming as of late, let alone modding. And I generally don’t pirate games. I’m cool with people that do, I just don’t personally. (Virus fears, being out of the loop long enough that I don’t know any good sites, etc)
virus fears
Honestly, if desktop operating systems supported better sandboxing of malware, I bet that piracy would increase.
why does ml3 need todie
It’s a 30 year old format, and large amounts of research and innovation in lossy audio compression have occurred since then. Opus can achieve better quality in like 40% the bitrate. Also, the format is, much like zip, a mess of partially broken implementations in the early days (although now everyone uses LAME so not as big of a deal). Its container/stream format is very messy too. Also no native tag format so it needs ID3 tags which don’t enforce any standardized text encoding.
Not the original poster, but there are newer audio codecs that are more efficient at storing data than mp3, I believe. And there’s also lossless standards, compared to mp3’s lossy compression.
How about tar.gz? How does gzip compare to zstd?
Both slower and worse at compression at all its levels.
What’s wrong with mp3
Big file size for rather bad audio quality.
I’ve yet to meet someone who can genuinely pass the 320kbps vs. lossless blind-test on anything but very high-end equipment.
People are able to on some songs because mp3 is poorly optimized for certain sounds, especially cymbals. However, opus can achieve better quality than that at 128k with fewer outliers than mp3 at 320k, which saves a lot of space.
Removed by mod
Oh, yeah, not arguing that Opus is the superior format. It 100% is. Not questioning that.
Indeed, the first place that gets hit by lower bitrates with MP3 is high frequencies. MP3 does have a pretty harsh cutoff at very high frequencies… that the vast majority of equipment can’t reproduce and most ears can’t hear. It’s relatively debated, some claim to be able to “feel” the overtones or something like that. I’m extremely sceptical, if I’m being honest. Last time I did the test - must have been a decade ago - I couldn’t distinguish lossless and high bitrate MP3 any more accurately than a coin toss.
We’re not talking lossless. The comment above specified Opus-encoded OGG, which is lossy.
For example, I converted my music library from MP3 to OGG Opus and the size shrank from 16 GB to just 3 GB.
And if converting from lossless to both MP3 and OGG Opus, then OGG does sound quite a bit better at smaller file sizes.
So, the argument here is that musicians are underselling their art by primarily offering MP3 downloads. If the whole industry would just magically switch to OGG Opus, that would be quite an improvement for everyone involved.
Yeah, I’m aware. I probably wasn’t clear. I think MP3 is just the default cause of immobilism. People still using “physical” medium/digital libraries rather than streaming are becoming a rare breed, and MP3 is just… good enough. Also familiarity - I remember googling “some song - some artist mp3” being the easy way to find single titles in my teenage years lol, if I wasn’t aware of the new codecs, I’d probably default to MP3 without asking myself the question.
Well, I understood this post to mean, if you had a wish, what would you wish for? Not necessarily that it’s realistic…
I do agree with your points. Although, I can’t help but feel like more people would prefer local files, if those actually sounded better than the bandwidth-limited streaming services.
I was expanding on the subject, generating side discussion stuff. Maybe I came across as standoffish - if that’s the case, I apologize.
I’m not sure how much people would care… Even back then, convincing people around me that their 128kbps MP3 sounded like it played on a tiny dollar store external speaker playing in a shower was almost impossible. Tons just download MP3s off of YouTube and call it a day. So many people don’t seem to care, unfortunately.
Convenience is the best motivator, IMHO. Downloading MP3s and loading them on your MP3 player used to be easy. You had sites literally letting you download songs directly. Torrents were big. Hell, going back, eMule/Kazaa, even Limewire, all was much easier than buying CDs and ripping them, or even when buying from online stores became a thing, with the DRM early on, etc, downloading was much less hassle.
Now people pay one price and get to listen to all the music they want to listen to.
yeah, but guess what opus is transparent at? depending on the music, anywhere from 96kbps to 160kbps.
320 kbps is approaching lossless audio compression bitrates.
Opus does better in about half the space. And goes down to comically low bitrates. And his obscenely small latency. It’s not simple, but hot dang, is it good.
The Quite Okay Imaging guy did a Quite Okay Audio follow-up, aiming for aggressive simplicity and sufficient performance, but it’s fixed at a bitrate of 278 kbps for stereo. It’s really competing with ADPCM for sound effects in video games.
Personally, I think an aggressively simple frequency-domain format could displace MP3 as a no-brainer music library format, circa 128 kbps. All you have to do is get forty samples out of sixty-four bits. Bad answers are easy and plentiful. The trick is, when each frame barely lasts a millisecond, bad answers might work anyway.
I think that people overstate MP3’s losses, and I agree at 320k that it’s inaudible, but I can or at least have been able to tell at 128k, mostly with cymbals. Granted, cymbals aren’t that common, but it’s nice to not have them sound muddy. And, honestly, there just isn’t a lot of reason to use MP3 for anything compressed today, other than maybe hardware decoding on very small devices and widespread support. There are open standards that are better.
Oh, for sure. See my other comments. Opus is probably my favorite as well.
its worth noting that aac is actually pretty good in a lot of cases too
However, it is very patent encumbered and therefore wouldn’t make for a good standard.
aac lc and he-aac are both free now hev2 and xhe aren’t, but those have more limited use
How about xz compared to zstd?
At both algorithms’ highest levels, xz seems to be on average a few percent better at compression ratio, but zstd is a bit faster at compression and much much faster at decompression. So if your goal is to compress as much as possible without regard to speed at all,
xz -9is better, but if you want compression that is almost as good but faster,zstd --long -19is the way to goAt the lower compression presets, zstd is both faster and compresses better
Removed by mod
How are you going to recreate the MP3 audio artifacts that give a lot of music its originality, when encoding to OPUS?
Oh, a gramophone user.
Joke aside, i find ogg Opus often sounding better than the original. Probably something with it’s psychoacoustic optimizations.
Removed by mod
I don’t know what to pick, but something else than PDF for the task of transferring documents between multiple systems. And yes, I know, PDF has it’s strengths and there’s a reason why it’s so widely used, but it doesn’t mean I have to like it.
Additionally all proprietary formats, specially ones who have gained enough users so that they’re treated like a standard or requirement if you want to work with X.
oh it’s x, not x… i hate our timeline
I would be fine with PDFs exactly the same except Adobe doesn’t exist and neither does Acrobat.
When PDF was introduced it made these things so much better than they were before that I’ll probably remain grateful for PDF forever and always forgive it all its flaws.
I would be fine with PDFs exactly the same except Adobe doesn’t exist and neither does Acrobat.
JPEG-XL for rasterized images.
I agree.
I especially love that it addresses the biggest pitfall of the typical “fancy new format does things better than the one we’re already using” transition, in that it’s specifically engineered to make migration easier, by allowing a lossless conversion from the dominant format.
Never heard of that, thanks for bringing it to my attention!
deleted by creator
GNOME introduced its support in version 45, AFAIK there isn’t a stable distro release yet that ships it.
Unfortunately, adoption has been slow and Alliance for Open Media are pushing back somewhat (especially Google[1], who leads the group) in favor of their inferior
.avifformat.
How does it compare to AVIF?
AVIF is slower, has a way smaller maximum resolution and doesn’t support progressive decoding as well as lossless JPEG recompression.
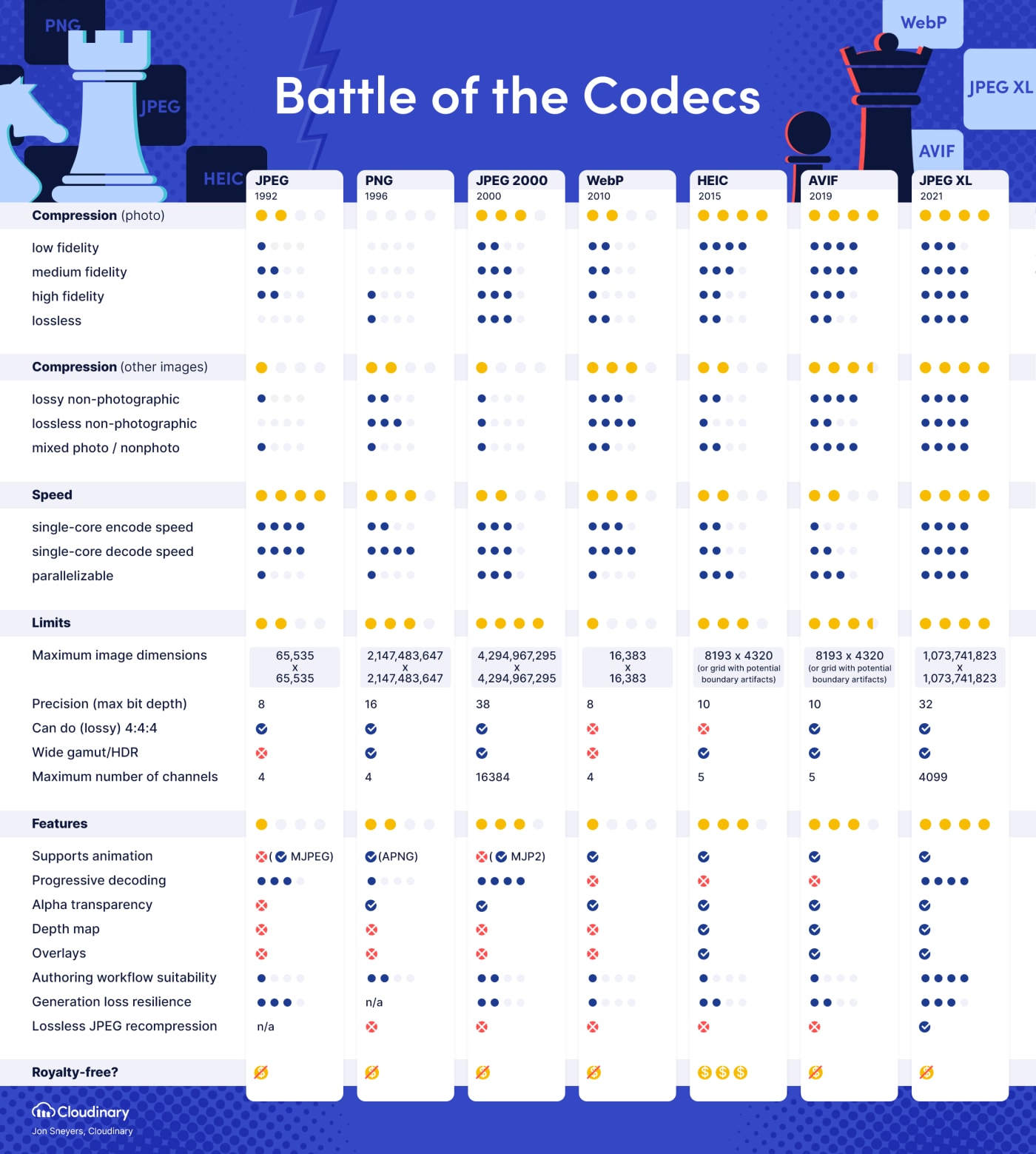
Oh dam, that resolution limit is a total deal breaker. Can’t believe anyone would release a format with those limitations today…
Literally any file format except PDF for documents that need to be edited. Fuck Adobe and fuck Acrobat
Isn’t the point of PDF that it can’t (or, perhaps more accurately, shouldn’t) be edited after the fact? It’s supposed to be immutable.
I’m not sure if they were ever designed to be immutable, but that’s what a lot of people use it for because it’s harder to edit them. But there are programs that can edit PDFs. The main issue is I’m not aware of any free ones, and a lot of the alternatives don’t work as well as Adobe Acrobat which I hate! It’s always annoying at work when someone gets sent a document that they’re expected to edit and they don’t have an Acrobat license!
I’ve already edited some pdfs with LibreOffice writer. I don’t know if it’s suitable for that, but it worked for me
PDFs can contain a vast amount of different Image information, but often a good software that can edit vector data opens PDFs for editing easily. It might convert not embedded Fonts in paths and rasterize some transparency effects though. So Inkscape might work.
I’m assuming that will work similar to Microsoft Word where it’s fine for basic PDFs but if there are a lot of tables or images it can mess up the document?
think of it as though pdf is the container - it can contain all sorts of different data. I’d say you got real lucky being able to edit one with Writer without issues.
I’ve confused the name, It was LibreOffice Draw, not Writer
Unless you have explicitly digitally-signed the PDF, it’s not immutable. It’s maybe more-annoying to modify, but one shouldn’t rely on that.
And there are ways to digitally-sign everything, though not all viewing software has incorporated signature verification.
No, it’s too preserve formatting when distributed. Editing is absolutely possible, always were, it’s just annoying to parse the structure when trying to preserve the format as you make changes
No, although there’s probably a culture or convention around that.
Originally the idea was that it’s a format which can contain fonts and other things so it will be rendered the same way on different devices even if those devices don’t have those fonts installed. The only reason it’s not commonly editable that I’m aware of is that it’s a fairly arcane proprietary spec.
Now we have the openspec odt which can embed all the things, so pdf editing just doesn’t really seem to have any support.
The established conventions around pdfs do kind of amaze me. Like contracts get emailed for printing & signing all the time. In many cases it would be trivial to edit the pdf and return your edited copy which the author is unlikely to ever read.
Hold on. I’m applying for a mortgage and I want the bank to pay off my loan for me after 6 months of payments.
Why would you use acrobat? I haven’t used it in many years and use PDFs all the time
What do you use?
Depends on the platform I’m on. There are so many options. SumatraPDF on windows, whatever default app pop os has, preview on Mac, builtin android PDF viewer. I assume you’re on windows because you mentioned acrobat. There are several options beside sumatra. I think many are decent.
Ah I was more looking for alternative editors rather than viewers, I usually just use my web browser to view them
Ah, yeah I normally would only need to do that in the context of signing a contract, which I do using Gimp or Photoshop.
Have you tried these? https://www.lifewire.com/best-free-pdf-editors-4147622
I have not, I’ll give some of them a try!
Firefox can edit PDFs , although I wouldn’t be surprised if it’s not in depth
Is foxit still around? I didn’t mind that one on windows.
Yup an it also one of best for linux
Acrobat Reader is actually great for filling out forms.
Even if the “pdf” is actually just a potato quality photo of what was at some time a form, you can still fill it out in Acrobat Reader.
Generally in windows I prefer sumatra pdf as a reader, but I keep acrobat around for this purpose.
Resume information. There have been several attempts, but none have become an accepted standard.
When I was a consultant, this was the one standard I longed for the most. A data file where I could put all of my information, and then filter and format it for each application. But ultimately, I wanted to be able to submit the information in a standardised format - without having to re-enter it endlessly into crappy web forms.
I think things have gotten better today, but at the cost of a reliance on a monopoly (LinkedIn). And I’m not still in that sort of job market. But I think that desire was so strong it’ll last me until I’m in my grave.
SQLite for all “I’m going to write my own binary format because I is haxor” jobs.
There are some specific cases where SQLite isn’t appropriate (streaming). But broadly it fits in 99% of cases.
To chase this - converting to json or another standardized format in every single case where someone is tempted to write their own custom parser. Never write custom parsers kids, they’re an absolutely horrible time-suck and you’ll be fixing them quite literally forever as you discover new and interesting ways for your input data to break them.
Edit: it doesn’t have to be json, I really don’t care what format you use, just pick an existing data format that uses a robust, thoroughly tested, parser.
To add to that. Configuration file formats…just pick a standard one, do not write your own.
And while we are at it, if there is even a remote chance that you have a “we will do everything declaratively” idea, just use an existing programming language for your file format instead of painfully growing some home-grown add-ons to your declarative format over the next decade or two because you were wrong about only needing a declarative format.
Also parquet if the data aren’t mutated much.
give me a category please
I’ll take “what’s that file format for $300 please”
Yeah, what was it? If office formats used sqlite instead of zip?
I wish there was a more standardized open format for documents. And more people and software should use markdown/.md because you just don’t need anything fancier for most types of documents.
Yes, but only if everyone adhere to CommonMark version of Markdown.
Nah, Pandoc Markdown is the true path.
why, what even is markdown
I agree, we need support for it in libreoffice and than other document editors.
We can not expect people to use codes, but editor that saves to it would be grat.
Standardized open format for documents might have been the only ISO meeting where people were protesting in the streets - https://en.wikipedia.org/wiki/Standardization_of_Office_Open_XML
So now ISO officially has two standard formats for the exact same thing!
Impressive! Thanks for sharing. I didn’t know there was a standard. So if someone sends me a docx I can ask them for an iso format now :)
Well, actually ODF came first, to which MS paniked (governments liking standards), so they then remade their office formats to OOXML. Except most of it proprietary extensions, 600 page confusing documentation, bribery during standardization (ECMA, they failed ISO), etc.
Data output from manufacturing equipment. Just pick a standard. JSON works. TOML / YAML if you need to write as you go. Stop creating your own format that’s 80% JSON anyways.
JSON is nicer for some things, and YAML is nicer for others. It’d be nice if more apps would let you use whichever you prefer. The data can be represented in either, so let me choose.
KDL enters the chat
I don’t give a shit which debugging format any platform picks, but if they could each pick one that every emulator reads and every compiler emits, that’d be fucking great.
Even more simpler, I’d really like if we could just unify whether or not
is needed for variables, and pick#or//for comments. I’m sick of breaking my brain when I flip between languages because of these stupid nuance inconsistencies.Don’t forget
;is a comment in assembly.For extra fun, did you know
//wasn’t standardized until C99? Comments in K&R C are all/* */. Possibly the most tedious commending format ever devised.;is also used by LISP.And there’s
REMin BASIC.Batch files also use
REM. Or::. Each of which causes syntax errors in completely different scenarios.M4 says it uses
#, but that’s an echo, anddnlis for real comments.CSS still forces K&R style, but on reflection, that’s nothing compared to HTML’s
⋖!-- -->nonsense. (Edit: or Lemmy’s idiotic erasure of HTML-like blocks. If they’re not allowed… show them as text, fools.)Fortran uses
!orCin the appropriate column.in the appropriate column.
Alright that’s just hideous.
Forth uses
\, and can do block comments with(and), except)is optional in interpreted mode.Algol 60 used
¢. ¢ isn’t even in ASCII, so god knows how that “your two cents” joke ever happened. How can a language this boring still exemplify how all programmers are dorks?Visual Basic uses
'because go fuck yourself. QBASIC origins or not, I don’t know how this shipped without at least one meeting where somebody got stabbed. Even the Systems Hungarian heretics should have recoiled in horror.Algol 60 used ¢. ¢ isn’t even in ASCII,
APL uses “⍝”, which isn’t even in any human language and was introduced specifically so that APL can have comments.
/* */is used in CSS as well, I think.Also we’ve got VB (and probably BASIC) out there using
'because why not lol[EDIT] I stand corrected by another comment
REMis what BASIC uses. DOS batch files use that, too. They’re old though, maybe we give them a pass “it’s okay grampa, let’s get you back to the museum” 🤣 (disclaimer: I am also old, don’t worry)
It does not work like that.
is required in shell languages because they have quoteless strings and need to be super concise when calling commands.#and//are valid identifiers in many languages and all of them are well beyond the point of no return. My suggestion is to make use of your editor’s “turn this line into line comment” function and stop remembering them by yourself.
That just sounds impossible given the absolute breadth of all platforms and architectures though.
One per-thing is fine.
deleted by creator
Epub isn’t supported by browsers
So you want EPUB support in browser and you have the ultimate document file format?
deleted by creator
Weasyprint kinda is that, except that it’s meant to be rendered to PDF.
Can you explain why you need browser support for epub?
EPubs are just websites bound in xhtml or something. Could we just not make every browser also an epub reader? (I just like epubs).
They’re basically zip files with a standardized metadata file to determine chapter order, index page, … and every chapter is a html file.
deleted by creator
Microsoft Edge’s ePub reader was so good! I would have used it all the time for reading if it hadn’t met its demise. Is there no equivalent fork or project out there? The existing epub readers always have these quirks that annoy me to the point where I’ll just use Calibre’s built in reader which works well enough.
I’d like an update to the epub ebook format that leverages zstd compression and jpeg-xl. You’d see much better decompression performance (especially for very large books,) smaller file sizes and/or better image quality. I’ve been toying with the idea of implementing this as a .zpub book format and plugin for KOReader but haven’t written any code for it yet.




























